 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverted Bilingual Topic Models for Lexicon Extraction from Non-parallel Data
Jun 21, 2017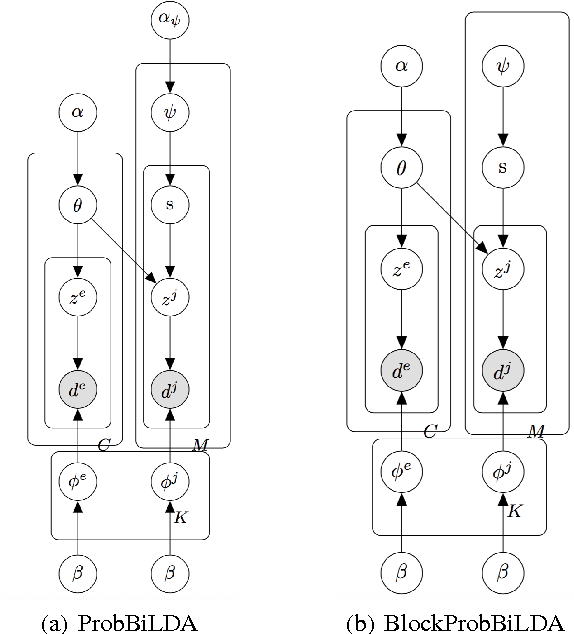
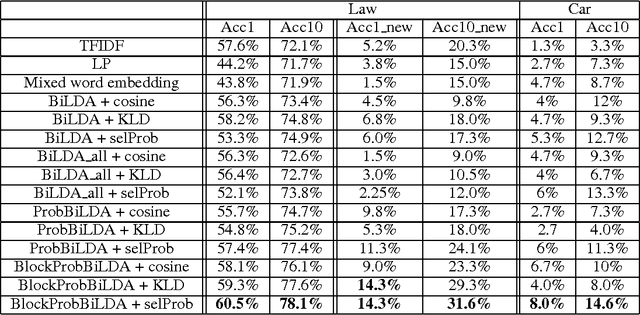
Topic models have been successfully applied in lexicon extraction. However, most previous methods are limited to document-aligned data. In this paper, we try to address two challenges of applying topic models to lexicon extraction in non-parallel data: 1) hard to model the word relationship and 2) noisy seed dictionary. To solve these two challenges, we propose two new bilingual topic models to better capture the semantic information of each word while discriminating the multiple translations in a noisy seed dictionary. We extend the scope of topic models by inverting the roles of "word" and "document". In addition, to solve the problem of noise in seed dictionary, we incorporate the probability of translation selection in our models. Moreover, we also propose an effective measure to evaluate the similarity of words in different languages and select the optimal translation pairs. Experimental results using real world data demonstrate the utility and efficacy of the proposed models.
Robust Parsing Based on Discourse Information: Completing partial parses of ill-formed sentences on the basis of discourse information
May 24, 1995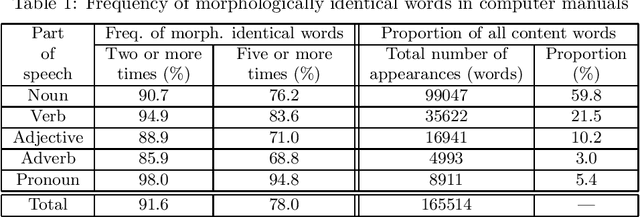


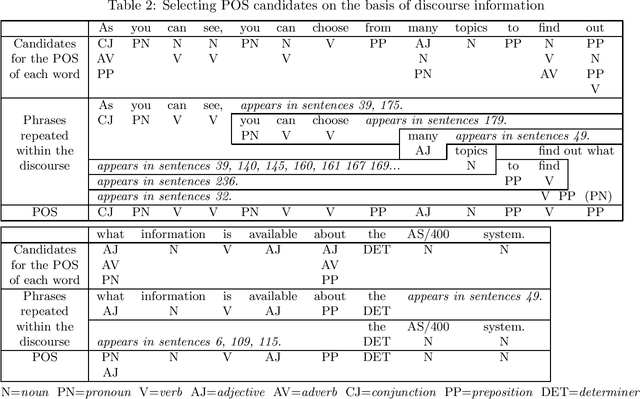
In a consistent text, many words and phrases are repeatedly used in more than one sentence. When an identical phrase (a set of consecutive words) is repeated in different sentences, the constituent words of those sentences tend to be associated in identical modification patterns with identical parts of speech and identical modifiee-modifier relationships. Thus, when a syntactic parser cannot parse a sentence as a unified structure, parts of speech and modifiee-modifier relationships among morphologically identical words in complete parses of other sentences within the same text provide useful information for obtaining partial parses of the sentence. In this paper, we describe a method for completing partial parses by maintaining consistency among morphologically identical words within the same text as regards their part of speech and their modifiee-modifier relationship. The experimental results obtained by using this method with technical documents offer good prospects for improving the accuracy of sentence analysis in a broad-coverage natural language processing system such as a machine translation system.